Unsupervised User Reputation for Crowdsourcing
Crowdsourcing is a common tool for extracting information from large amounts of data that is too difficult to be recognized automatically. This is achieved by distributing the workload among a large crowd of human workers.
To ensure the quality of the extracted information, multiple users are usually asked to perform the task on the same item. However, finding the truth among all annotations obtained for a single item is often non-trivial, especially when there are only few annotations that item.
On the other hand, if the users have annotated other items as well, it is possible to measure their mutual agreement with each other and automatically determine a reputation score for each user, without actually knowing how close their annotations are to the truth. The reputation scores can then be used to aggregate all annotations for a certain item giving higher weights to the information provided by more reputable users.
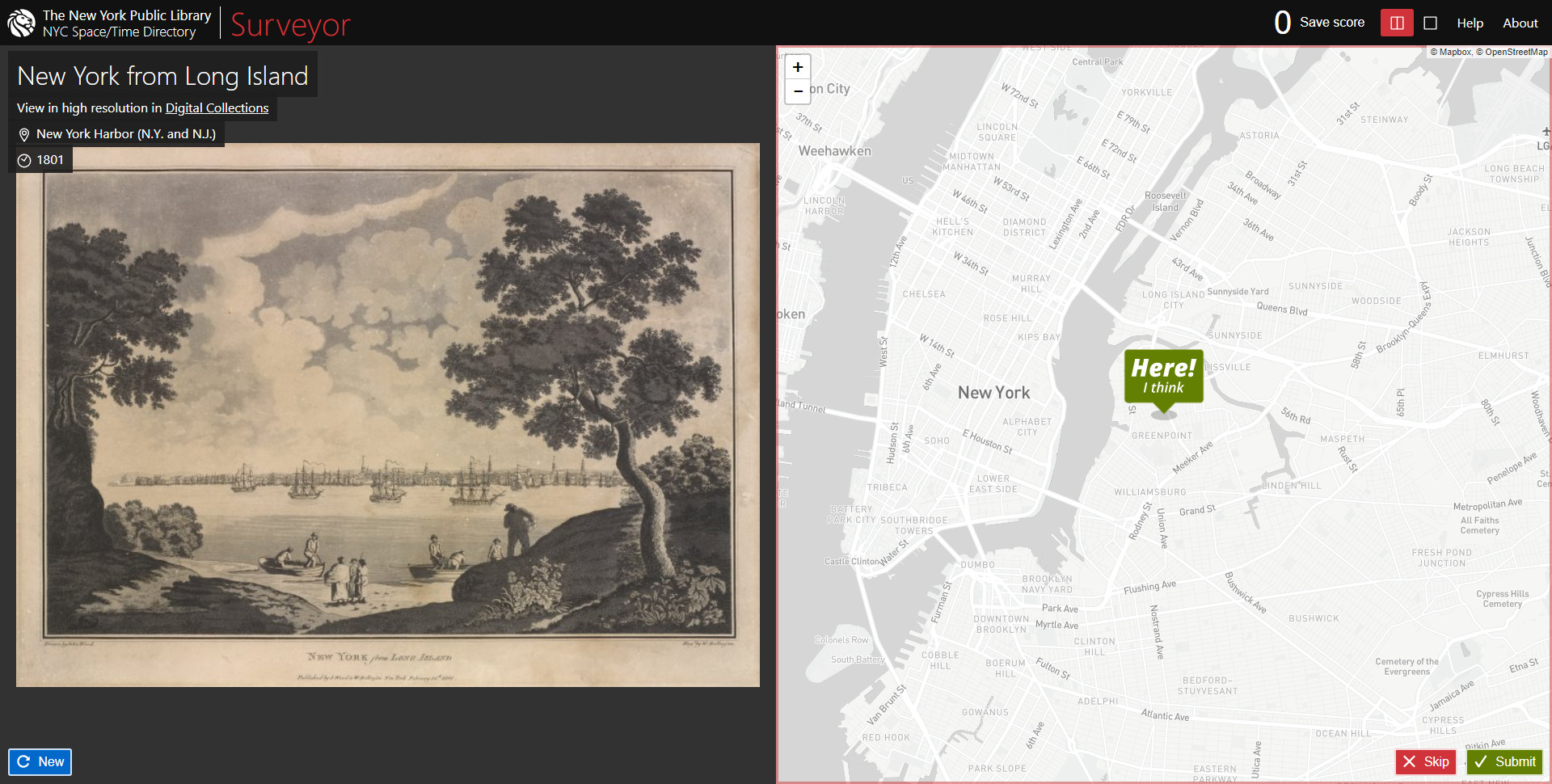
We demonstrate our approach on a dataset of historical photos from the New York Public Library (NYPL), where the users have been asked to locate the photographer’s position and the viewing direction on a map (see figure). We also obtained some interesting insights into the data and the behaviour of crowdworkers by analyzing the user graph and the reputation scores.
In the future, we plan to apply this method also to the task of extracting house numbers and polygons from historical maps.